Aktuelle Ausgabe

Unsere Partner
P3 1-2/2025 de
Was bedeutet eigentlich ...
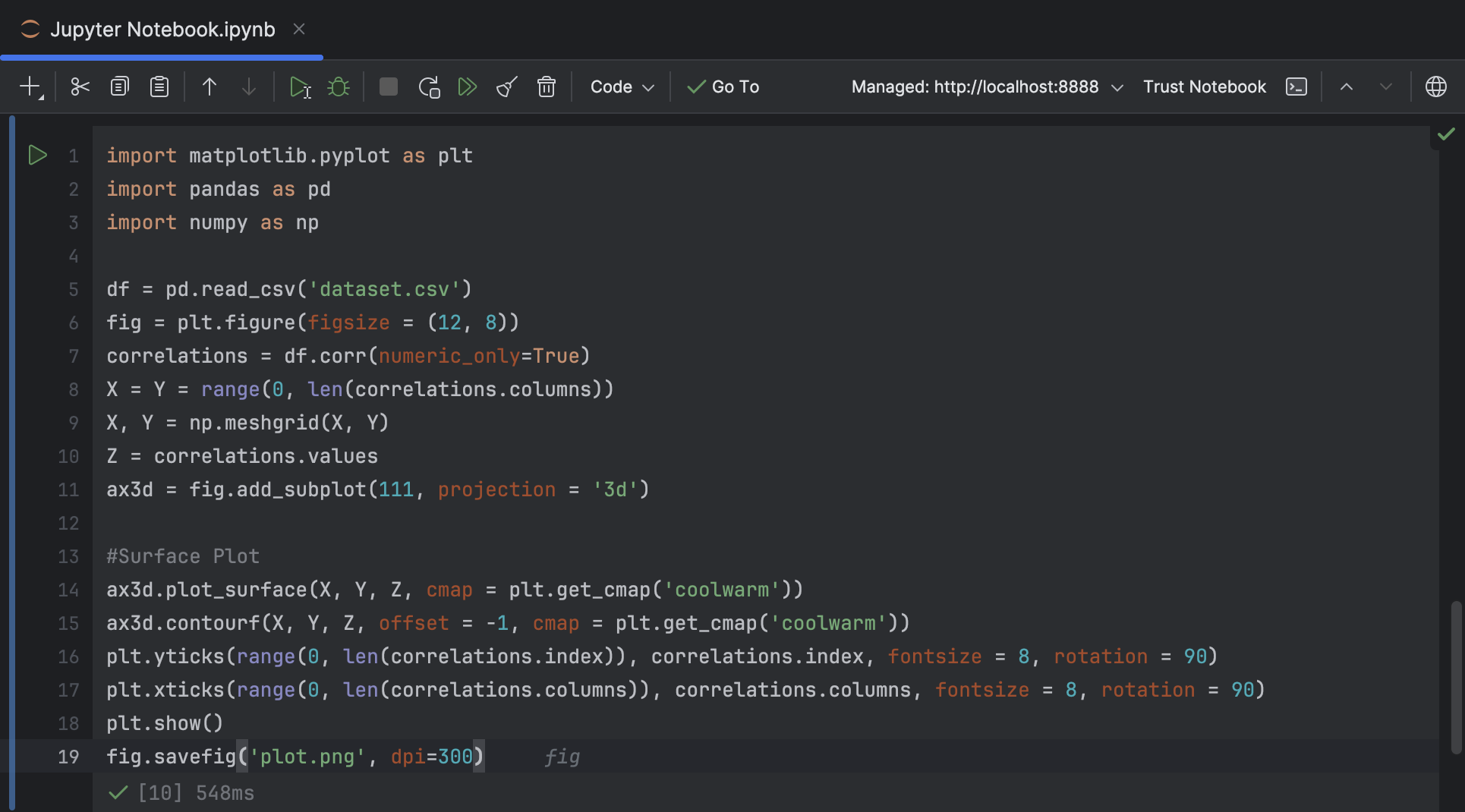
Jupyter Notebook
Bildungslücke
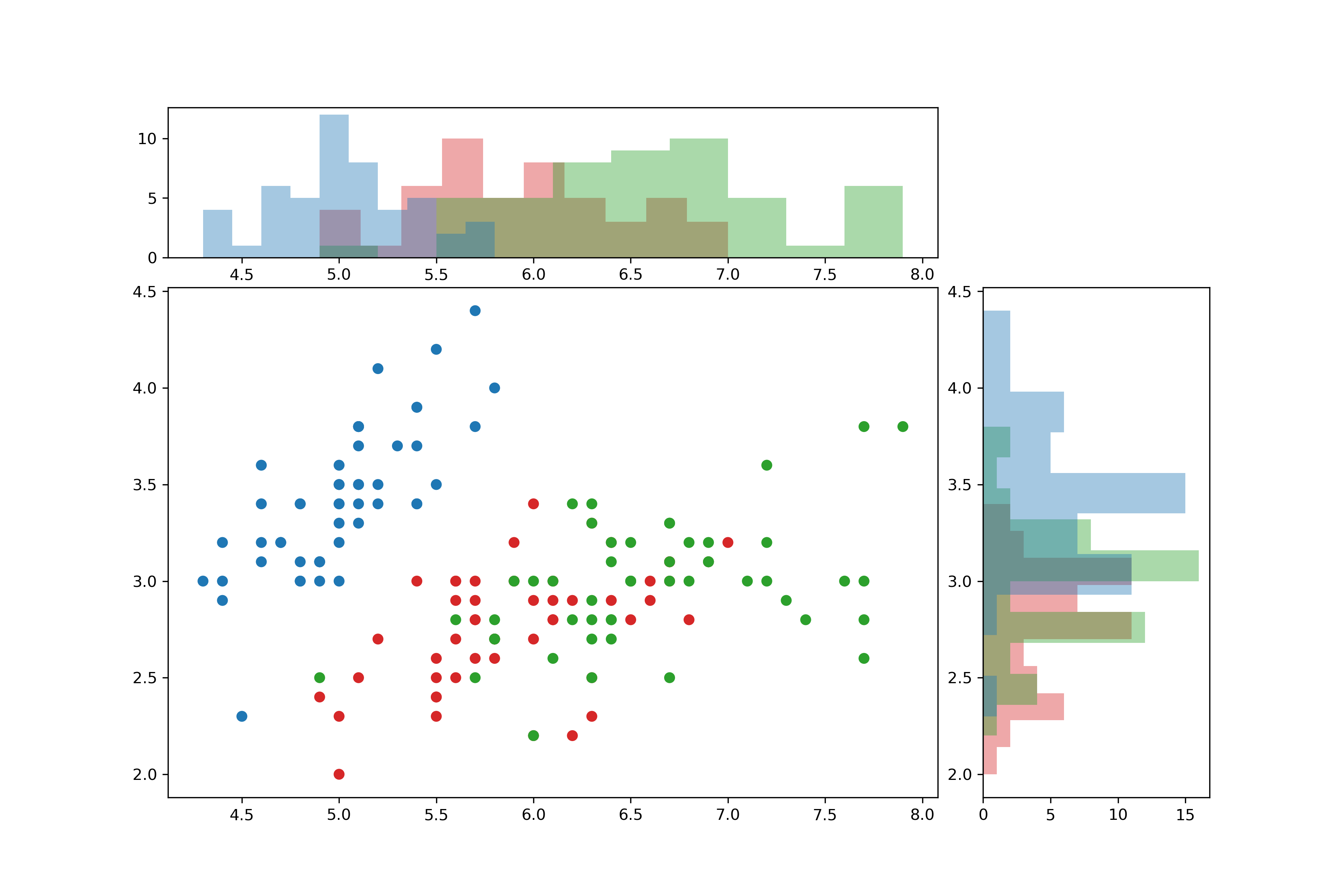
Ein Scatter-Plot mit zwei Histogrammen als Ausgabe eines Jupyter-Notebooks.

Jupyter Notebooks gehören nicht zu den Dingen, die Sie beim Saturn-Verkäufer Ihres Vertrauens kaufen und in bar bezahlen. Vielmehr befinden wir uns hier im Bereich big data. Bei Jupyter Notebooks handelt es sich um eine Software-Anwendung, die in erster Linie zur Analyse und Visualisierung großer Datenmengen dient - gerne auch live und in Echtzeit. Die Mappen mit dem etwas sperrigen Dateikürzel ipynb können aber auch einfach gespeichert und weitergegeben werden.
Ein Scatter-Plot mit zwei Histogrammen als Ausgabe eines Jupyter-Notebooks.
Qu'est-ce que c'est?
Aus der offiziellen Beschreibung: „Ein Notebook ist ein gemeinsam nutzbares Dokument, das Computercode, Beschreibungen in einfacher Sprache, Daten, umfangreiche Visualisierungen wie 3D-Modelle, Diagramme, Grafiken und Abbildungen sowie interaktive Steuerelemente enthält. Zusammen mit einem Editor (wie JupyterLab) bietet ein Notebook eine schnelle interaktive Umgebung zum Prototyping und Erklären von Code, zum Erkunden und Visualisieren von Daten und zum Austausch von Ideen mit anderen.“
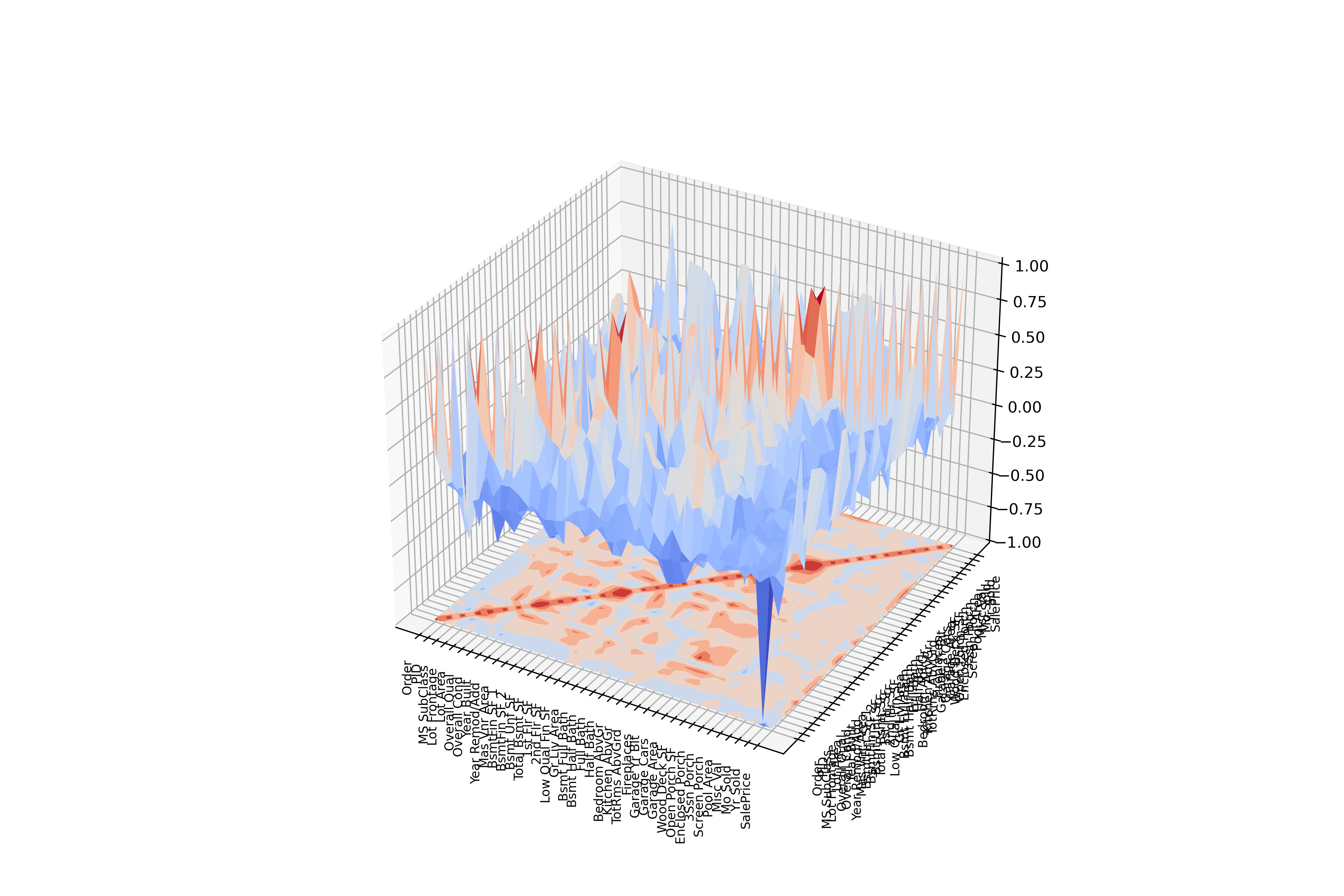
Jupyter Notebooks bestehen im Grundsatz aus einer beliebigen Kombination von Code Cells und Markup Cells. Während die letztgenannten dafür gedacht sind, textuale Beschreibungen und Erläuterungen aufzunehmen, wird in Code Cells skriptähnlich programmiert. Der Code kann - isoliert für jede Zelle - ausgeführt und modifiziert werden und liefert unmittelbar Ergebnisse, z.B. visuelle Darstellungen der Daten. Neben klassischen Balkendiagrammen und Tortengrafiken stehen auch anspruchsvollere Visualisierungen wie z.B. Box Plots, Scatter Plots, Matrizen und sogar 3D-Plots zur Verfügung. Allen Grafiken gemein ist, dass sie sehr umfachreich konfiguriert werden können, womit sich Jupyter Notebooks ohne weiteres auch für Präsentationen, Workshops oder Videokonferenzen eignen.
Arbeitsumgebung
Die einfachste Art, ein Jupyter Notebook zu erstellen und auszuführen, ist die Nutzung der Weboberfläche JupyterLab im Browser. Ernsthafte Interessenten werden eine lokale Installation bevorzugen und die umfangreiche Dokumentation zu Rate ziehen. Das volle Potenzial entfalten Sie schließlich mit der maximalen Kontrolle: Als Bestandteil einer integrierten Entwicklungsumgebung (IDE) wie z.B. JetBrains DataSpell oder PyCharm, die Jupyter-Support von Hause aus mit an Bord haben, ist das System für alle professionellen Anwendungsfälle gerüstet.
Jupyter Notebooks können mit verschiedenen Programmiersprachen genutzt werden. Als erster Schritt wird dafür ein Sprachkern, ein sogenannter Kernel, geladen. Zwar gibt es Sprachkerne für viele gebräuchliche Sprachen wie z.B. Java, PHP oder Dart; in der Datenanalyse und -aufbereitung gelten diese aber eher als Exoten. In 99 Prozent der Fälle wird man zu Python greifen, der Standardsprache für diese Art von Anwendungen - eventuell ergänzt um R, eine Skriptsprache, die sich insbesondere für Anwendungen der Statistik eignet. Der große Vorteil von Python liegt - neben der unkomplizierten Einrichtung einer entsprechenden Arbeitsumgebung - in der Verfügbarkeit einer Vielzahl an Bibliotheken, die genau für diese Problematiken erstellt wurden und langjährig erprobt und bewährt sind. Die klassischen Libraries hören auf die Namen pandas, numpy, seaborn und natürlich matplotlib. Sie alle sind kostenfrei verfügbar, entweder separat oder - komfortabler - als Bestandteil einer fertigen Python-Distribution wie z.B. Anaconda.
Natürlich hat jede Programmiersprache zunächst einmal eine mehr oder weniger steile Lernkurve. Da macht auch Python keine Ausnahme. In die Tiefe der Programmkonstrukte werden Sie jedoch nur in wenigen Fällen eintauchen müssen; Datenaufbereitung und grafische Darstellung lassen sich oft schon mit wenigen Zeilen Code realisieren. Am Ende des Beitrages finden Sie weiterführende Literaturhinweise, welche Sie recht stabil auf Schiene bringen sollten.
Dabei spielt es grundsätzlich keine Rolle, um was für Daten es sich handelt. Umsätze oder andere Finanzdaten, Marktanalysen oder Protokoll- bzw. Wartungsdaten einer Anlage aus der Produktion - alles ist möglich. Je nach Qualität des Datenmaterials kann vorher eine gewisse Aufbereitung erforderlich sein, aber auch hierfür bieten die Python-Bibliotheken - allen vorweg pandas und seaborn - alle benötigten Werkzeuge. Das schließt den Umgang mit für die Datenverarbeitung „logischen“ Dateiformaten ein: CSV- und XLSX-Dateien lassen sich mit einer einzigen Codezeile laden, aber auch der direkte Zugriff auf eine SQL-Datenbank (auch remote) ist möglich. Letztlich steht in einer IDE über die genannten Bibliotheken hinaus der gesamte Umfang von Python zur Verfügung.
Weiterführende Literatur
Landup, D.: Data Visualization in Python with Matplotlib and Pandas (StackAbuse)
Vanderplas, J.: Python Data Science Handbook (O'Reilly)
McKinney, W.: Python for Data Analysis (O'Reilly)