Aktuelle Ausgabe

Unsere Partner
P3 1-2/2023 de
Was bedeutet eigentlich ...
Verlustfreie Kompressionsverfahren
Bildungslücke
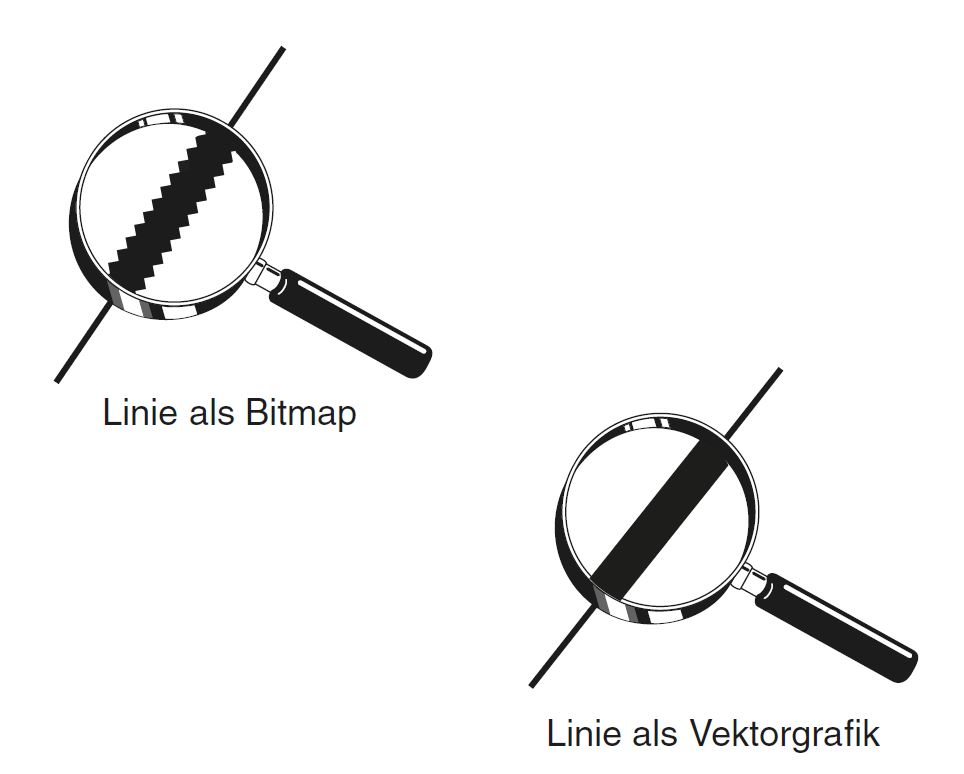
Abb. 1: Pixel- vs vektorbasierte Abbildungen.

Die Komprimierung von pixelbasierten Dateien ist aus der heutigen Medienlandschaft nicht mehr wegzudenken - das schließt den Digitaldruck mit ein. Verlustbehaftete Kompressionsverfahren sind nicht zuletzt dank des jpg-Formates jedermann bekannt. Anders sieht es mit den Verfahren aus, die zum Einsatz kommen, wenn eine verlustfreie Komprimierung gefordert ist, das Original also ohne Farb- und sonstige Fehler wiederherstellbar sein muss. Über die Grundlagen solcher Methoden informiert Fachautor Jürgen Heuer vom Adolph-Kolping-Berufskolleg in Münster.
Abb. 1: Pixel- vs vektorbasierte Abbildungen.
Abbildungen können grundsätzlich in zwei Gruppen unterteilt werden. Das sind zum einen die pixelbasierten Abbildungen und zum anderen die sog. vektororientierten Abbildungen (siehe Abbildung 1). Bei den pixelbasierten Abbildungen spricht man im Allgemeinen von Bildern, während man bei den vektororientierten Abbildungen auch von Illustrationen oder Grafiken spricht. Soll beispielsweise eine Linie dargestellt werden, ist dies pixelbasiert ausschließlich durch das Aneinanderreihen einzelner Pixel möglich. Jedes Pixel beschreibt hierbei einen definierten Punkt dieser Linie. Vektororientiert würde die Linie mathematisch lediglich durch Angabe des Start- und des Endpunktes beschrieben. Heute werden pixelbasierte Bilddaten mittels Digitalkameras erfasst oder (selten) mit Hilfe eines Scanners in digitale Daten konvertiert.
Des Weiteren lässt sich ein Pixel bei der Bildbearbeitung auch in der Graustufe verändern. Ein Pixel ist im Bereich der digitalen Bildverarbeitung in der Regel mit 8 Bit (1 Byte) kodiert. Es kann dadurch 256 verschiedene Zustände annehmen (von 0 = schwarz bis 255 = weiß) -> Abbildung 2.
Unter Kompression versteht man in erster Linie das Zusammenfassen gleicher Daten. Im folgenden Beispiel ist eine Pixelreihe mit 8 Pixeln dargestellt (Position 1 bis 8). Jedes Pixel kann genau zwei unterschiedliche Zustände annehmen (die Farbtiefe entspricht damit in diesem Fall einem Bit).
Um diese Pixelreihe (Abbildung 3) zu beschreiben, kann wie folgt vorgegangen werden:
- Position 1: Schwarz (bzw. Wert 1)
- Position 2: Schwarz
- Position 3: Schwarz
- Position 4: Schwarz
- Position 5: Schwarz
- Position 6: Weiß (bzw. Wert 0)
- Position 7: Weiß
- Position 8: Weiß
Durch diese Angaben wäre die abgebildete Pixelreihe unmissverständlich beschrieben. Stellt man sich die Frage, ob diese Pixelreihe nicht viel einfacher und vor allen Dingen kürzer beschrieben werden kann, ist es offensichtlich, dass die Anzahl der schwarzen und weißen Pixel zusammengefasst werden kann:
- Position 1 bis 5: Schwarz
- Position 6 bis 8: Weiß
Bei dem oben dargestellten Kompressionsverfahren (Run Length Encoding oder dt. Lauflängenkodierung) kann die ursprüngliche Pixelreihe ohne Probleme wieder rekonstruiert werden. Man spricht dann von verlustfreier Kompression. Aus dem Beispiel ist ersichtlich, dass die Kompressionsmöglichkeit mit dem Aufbau der Pixelreihe im Zusammenhang steht. Im günstigsten Fall wird Position 1 bis 8 komplett mit schwarzen bzw. weißen Pixeln belegt und man erreicht die höchsten Kompressionsraten. Im ungünstigsten Fall (schwarze und weiße Pixel wechseln sich ständig ab) wird man mit diesem Verfahren überhaupt keine Kompression erzielen.
Ein weiterer Ansatz der verlustfreien Komprimierung soll an dieser Stelle zur Verdeutlichung dargestellt werden. In der Abbildung 4 sind 8 Pixelreihen dargestellt. Schaut man sich diese Pixelreihen genauer an, stellt man fest, dass sich die Reihen 1 und 2 wiederholen bzw. ein wiederkehrendes Muster bilden (Blau hinterlegt). Dieses Muster könnte jetzt in einer Tabelle (Wörterbuch) gespeichert und bei Bedarf aufgerufen werden.
Das Wörterbuch baut sich dabei dynamisch auf. In dem Beispiel in Abbildung 4 würde z. B. erst die Position 1/1 (1) als erster Eintrag gesichert, dann die Positionen 1+2 (11), dann 1+2+3 (111) usw.. So würden sich dann automatisch wiederkehrende Muster enstprechend entwickeln und diese werden gesichert. Die sich dadurch ergebende Kompression wäre um ein Vielfaches größer, als bei der Lauflängenkodierung, da wiederkehrende Bereiche aus einer Bilddatei komplett abgespeichert und beliebig oft aufgerufen werden können. Ein Verfahren, das nach diesem Ansatz arbeitet, ist das LZW-Verfahren, das z.B. bei TIF-Dateien eingesetzt wird. Auch die TIF-Ausgabedaten eines RIPs werden oft nach diesen Verfahren komprimiert, siehe Abbildung 5.
Abschließend kann dann auch die Frage beantwortet werden, wie sich die resultierende Dateigröße bei Verwendung eines verlustfreien Kompressionsverfahrens, wie z.B. dem LZW-Verfahren, entwickelt, wenn man ein FM-Raster einsetzt.

Abb. 2: Graustufen in der 8-Bit-Pixeldarstellung.
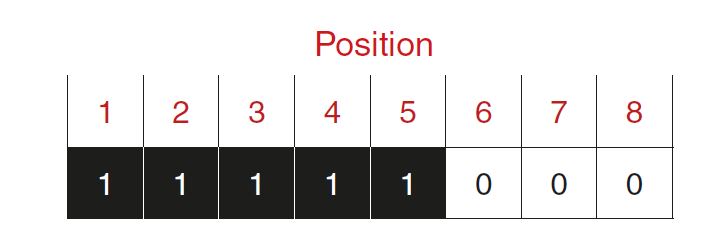
Abb. 3: Pixelreihe mit binären Zuständen.
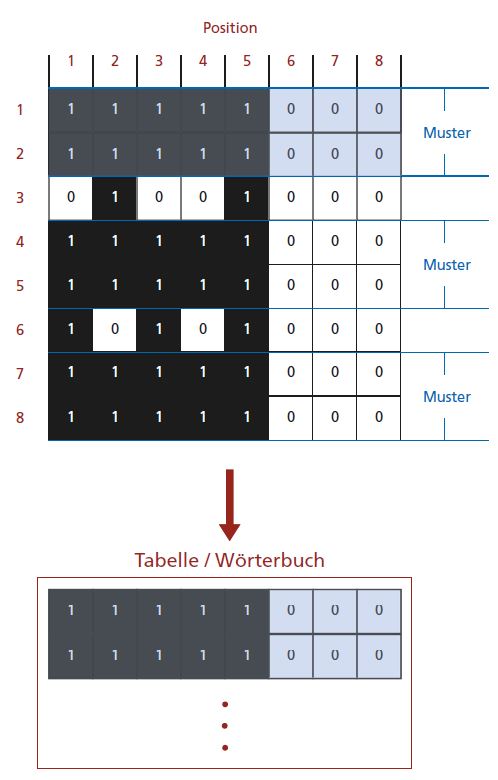
Abb. 4: Verlustfreie Komprimierung via Dictionary.
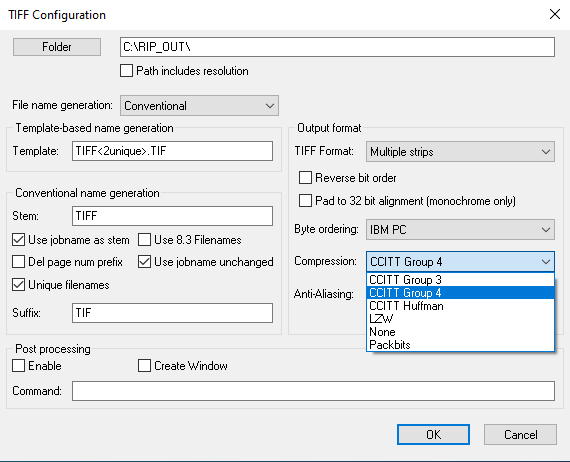
Abb. 5: G4-Kompression einer TIF-Dateiausgabe.

Autor: Jürgen Heuer
Redaktion: sbr
Abbildungen: Jürgen Heuer

